

Optimization problems exist all around us in various forms. They come in all scales, from a manager assigning tasks to employees in the best possible way to a logistics company planning its vehicle routes to save fuel.
These are all optimization problems. Solving these problems fast and accurately is important for businesses, but it’s often challenging. That’s because these problems are combinatorial in nature, which means they involve many different combinations, and trying them all would take a large amount of time.
Branch-and-Bound (BnB) is one of the most common ways to solve these kinds of problems. Think of a big decision tree where each point (called a node) is a partial solution and it is necessary to explore different paths to find the best complete solution. Instead of exploring every possible path, BnB eliminates paths that are unlikely to lead to the best solution, and saves a lot of time and computational effort. At each node, the algorithm makes two key decisions:
This second decision of selecting the variable to branch on has a huge impact on how efficiently the algorithm finds the optimal solution.
One way to decide which variable to branch on is called strong branching. Strong branching tries out each possible option temporarily. For each variable that can be branched on, the algorithm:
It then picks the variable that gives the strongest improvement, and eliminates all other branches from further exploration, which makes it very accurate and effective at reducing the search space. It gives high-quality decisions that usually lead to quality solutions, but it’s also very slow and expensive, especially for large problems, and can’t be used all the time during solving .
Since strong branching is slow to use throughout the entire solve, traditional BnB algorithms use a faster alternative called pseudocost branching. Here’s how it works:
This method is much faster because it doesn’t simulate or test each integer infeasible variable like in strong branching. But, it comes with a trade-off; when there is not much historical branching data collected, pseudocost estimates can be unreliable and can lead to poor branching decisions, especially in the early stages of the BnB process.
We’re exploring whether machine learning (ML) can improve how BnB decides which variable to branch on. We call this ML-BVS, which stands for: Machine Learning-Branch Variable Selection. The idea is simple: Use ML to learn from good branching decisions (using real data), and then use that learning to make better decisions for branching on the variables in the problem.
We’ve designed a process with three main steps:
We first collect training data using strong branching. As stated earlier, Strong branching is slow and expensive, we only use it in the training phase to generate high-quality data. We record:
We feed this data into a machine learning model, which looks for patterns and combines the features that lead to the best branching decisions. We tested different ML models like:
We freeze the model after training, which means we lock in what it has learned and only use it to make predictions (i.e. infer the next branching variable), to eliminate need for costly strong branching. The ML model predicts the best branching variable at each node in the BnB tree during the process of solving the optimization problem.
Here’s how that looks in practice:
We did controlled experiments to test the performance of the ML models as a branching variable selection strategy on various benchmark problems from the MIPLIB2017 dataset. Specifically, we asked:
For testing, and to answer these questions, we ran experiments on several benchmark problems from MIPLIB2017. Each problem was solved using four different branching strategies:
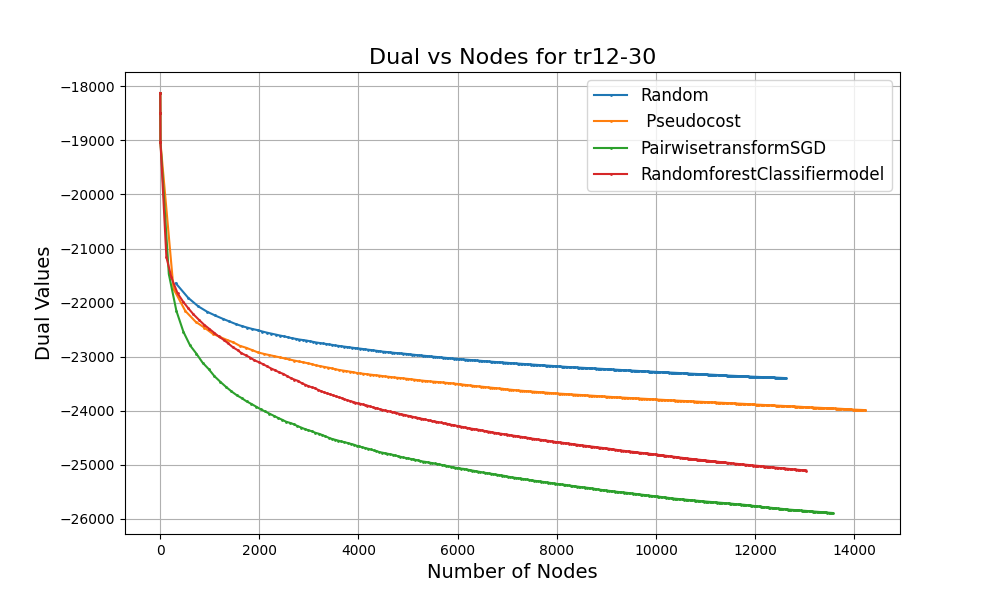
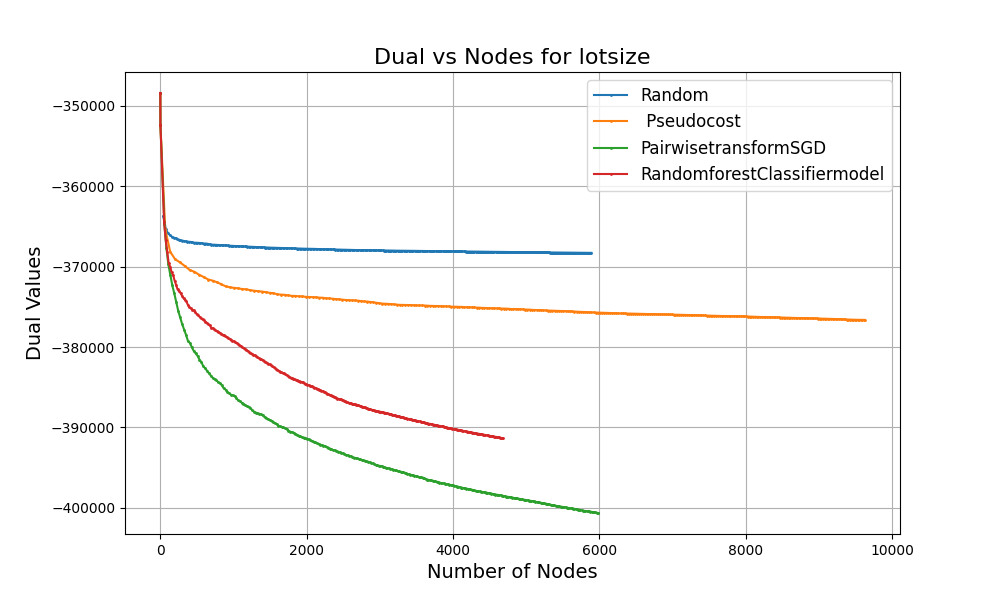
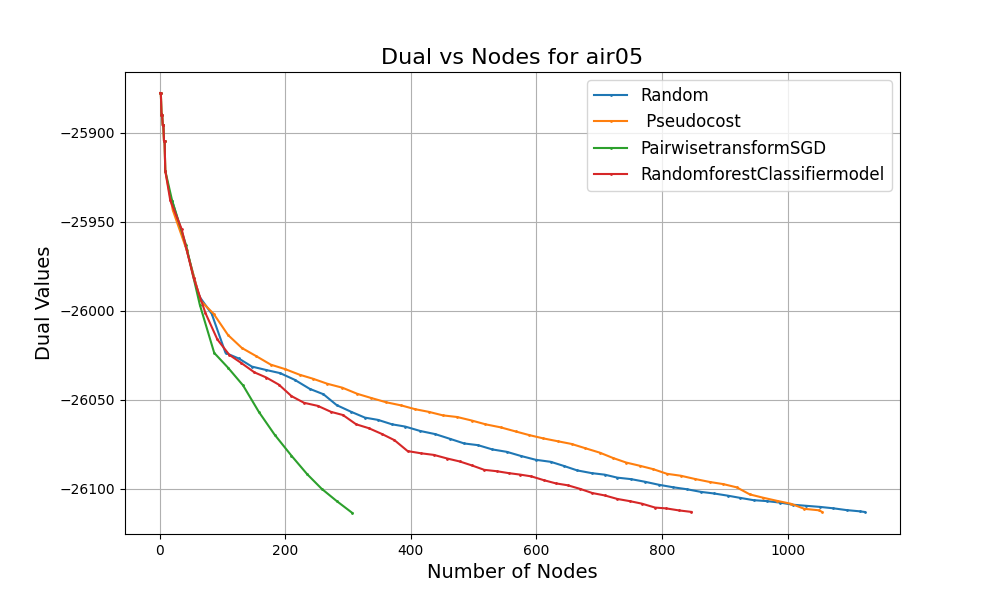
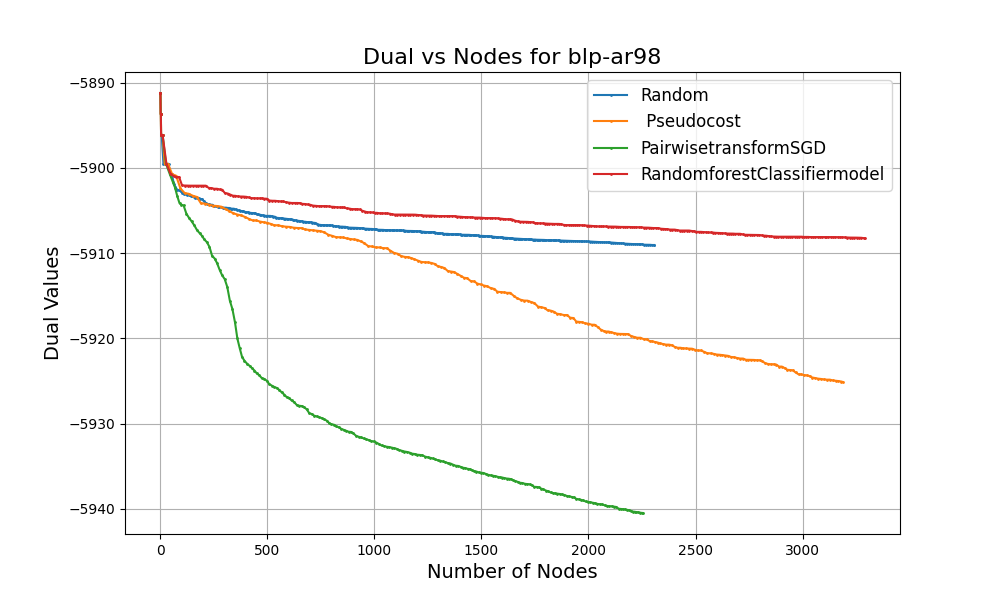
These graphs show some of the results that we observed. At every step in the optimization, we tracked:
In the plots:
The goal is to shrink the dual bounds faster - i.e. steeper curves in the plot (for minimization problems) - in the fewest number of node evaluations. Each curve on the graph shows how the dual value improves as the MIP solver traverses the branch and bound tree. You will notice:
These results confirm our hypothesis: machine learning can help branch-and-bound solvers make smarter decisions, especially in the early stages of solving complex problems.
While pseudocosts are calculated during the solve process and require branching multiple times on the same variable to be useful, ML models are pre-trained on high-quality strong branching data at the onset and can yield good decisions even early on in the branch and bound process. This provides evidence that choosing the right ML model for branching variable selection leads to tighter bounds and reducing node exploration times.
We will continue working on:
We’re excited to continue this exploration, and we’ll keep sharing what we learn.
